MarkItDownが文書処理を揃える理由
MarkItDown を一言でいうと、PDF、PowerPoint、Word、Excel、画像、音声、HTML、CSV、JSON、XML、EPUB、ZIP、YouTube URL など、入力形式がバラバラな情報を「LLM が扱いやすい Markdown」にそろえるための軽量な Python ツールです。README では textract に近い立ち位置と説明されていますが、違いは単なるテキスト抽出ではなく、見出し、リスト、表、リンクといった文書構造を Markdown として残そうとしている点にあります。ここが本質です。AI やエージェントの実務では、モデルの前段で入力を正規化できるかどうかが、その後の検索、要約、抽出、ワークフロー自動化の安定性を大きく左右します。
MarkItDownが解いているのは“文書ごとのバラつき”問題
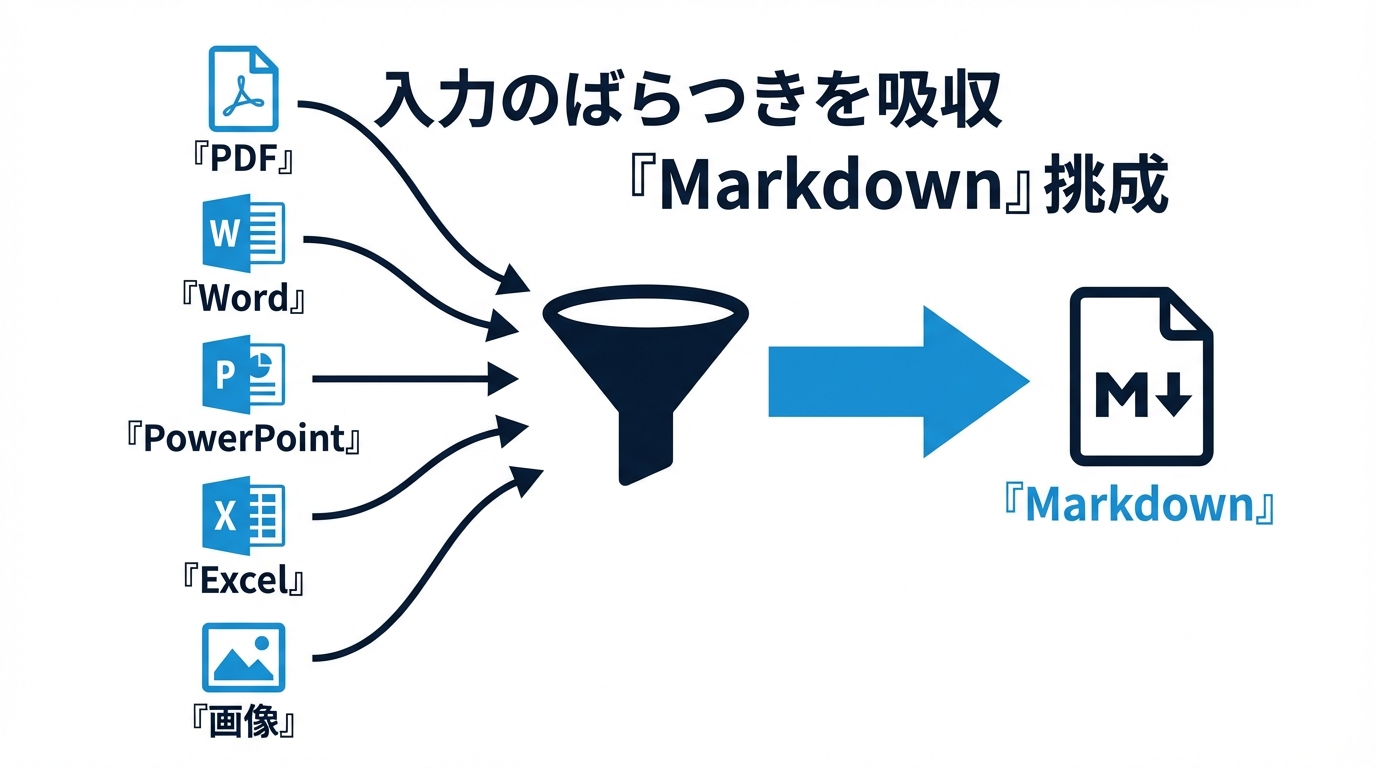
現場の文書処理は、想像以上に入力が散らかります。契約書は PDF、営業資料は PPTX、議事録は DOCX、集計表は XLSX、添付画像にはスクリーンショット、さらに ZIP の中に関連ファイルが固まっている。これをそのまま LLM に投げると、前処理ごとに別ロジックが増え、パイプラインがすぐ壊れます。
MarkItDown はこの前段をそろえるための部品です。CLI なら markitdown path-to-file.pdf > document.md のように使え、Python API でも MarkItDown().convert(...) で統一的に呼べます。重要なのは、個別形式ごとに別々の downstream 処理を書くのではなく、最終的な受け口を Markdown に寄せられることです。すると後段では、RAG の chunking、要約、分類、情報抽出、差分比較、レビュー支援といった処理を、ほぼ同じテキスト系パイプラインで回しやすくなります。
つまり MarkItDown の価値は「PDF を読める」こと自体ではありません。形式差を吸収して、AI が読む直前の表現をそろえることです。エージェント実装で言えば、これはモデル選定より地味ですが、再利用性と保守性に直結するレイヤーです。
なぜMarkdown正規化がAIと相性がいいのか
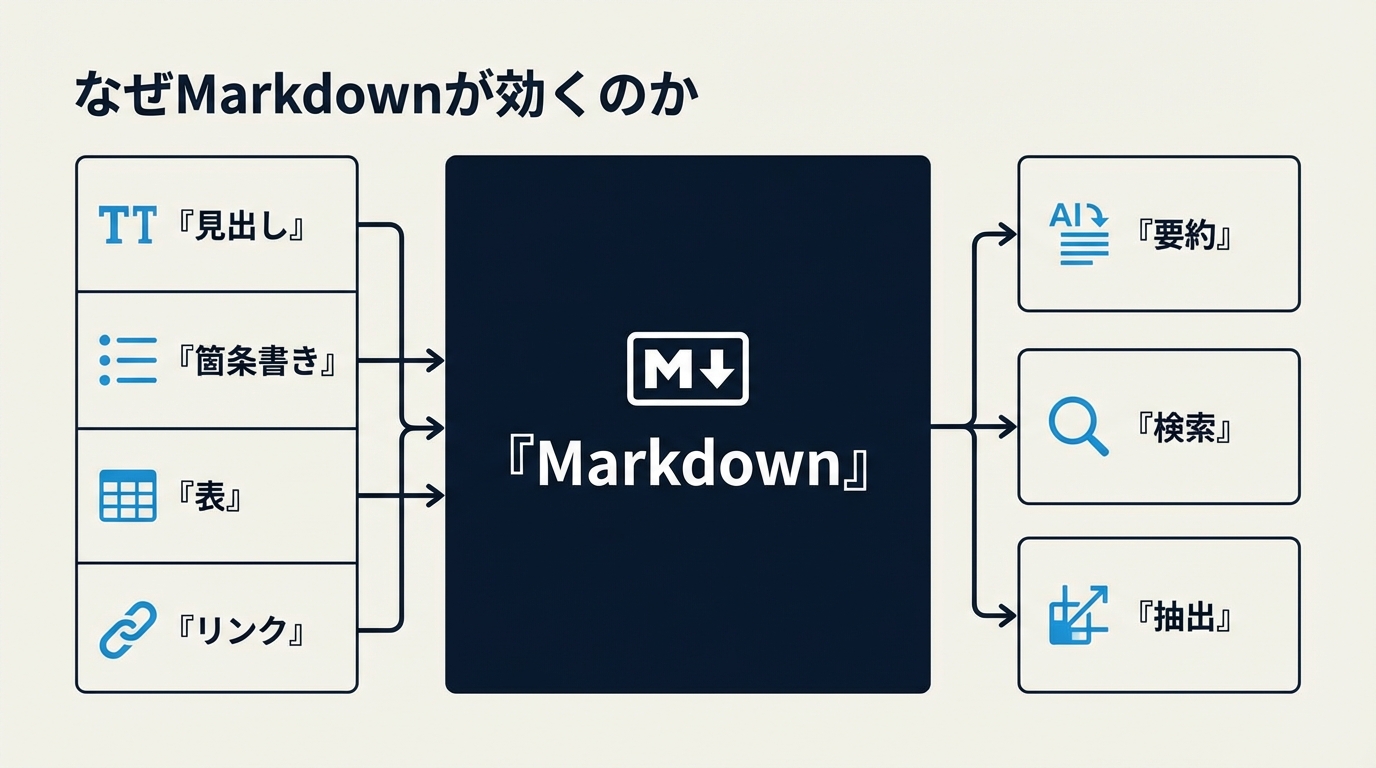
README がはっきり書いている通り、Markdown は plain text に近い一方で、見出し、箇条書き、表、リンクなどの重要な構造を保持できます。しかも LLM は Markdown を自然に扱うことが多く、トークン効率もよい。ここが実務上かなり効きます。
たとえば PDF を無理やり生テキスト化すると、表が崩れ、箇条書きが連結し、どこが章タイトルかも分かりにくくなります。一方で Markdown にそろえると、少なくとも次の利点が残ります。
##や###によってセクション境界を保ちやすい- 箇条書きや表が残るので、要点抽出や比較がしやすい
- リンクやメタ情報を後段に渡しやすい
- RAG 用の chunk 分割で意味単位を切りやすい
AI エージェントの観点では、この正規化は「読むための準備」ではなく「考えるための地盤」です。複数のツールをまたぐエージェントほど、入力形式の違いで毎回つまずきます。文書を Markdown にそろえておけば、要約 agent、検索 agent、レビュー agent、記録 agent のあいだで、受け渡し形式を共通化しやすくなります。
MarkItDownはAIパイプラインのどこに入るのか
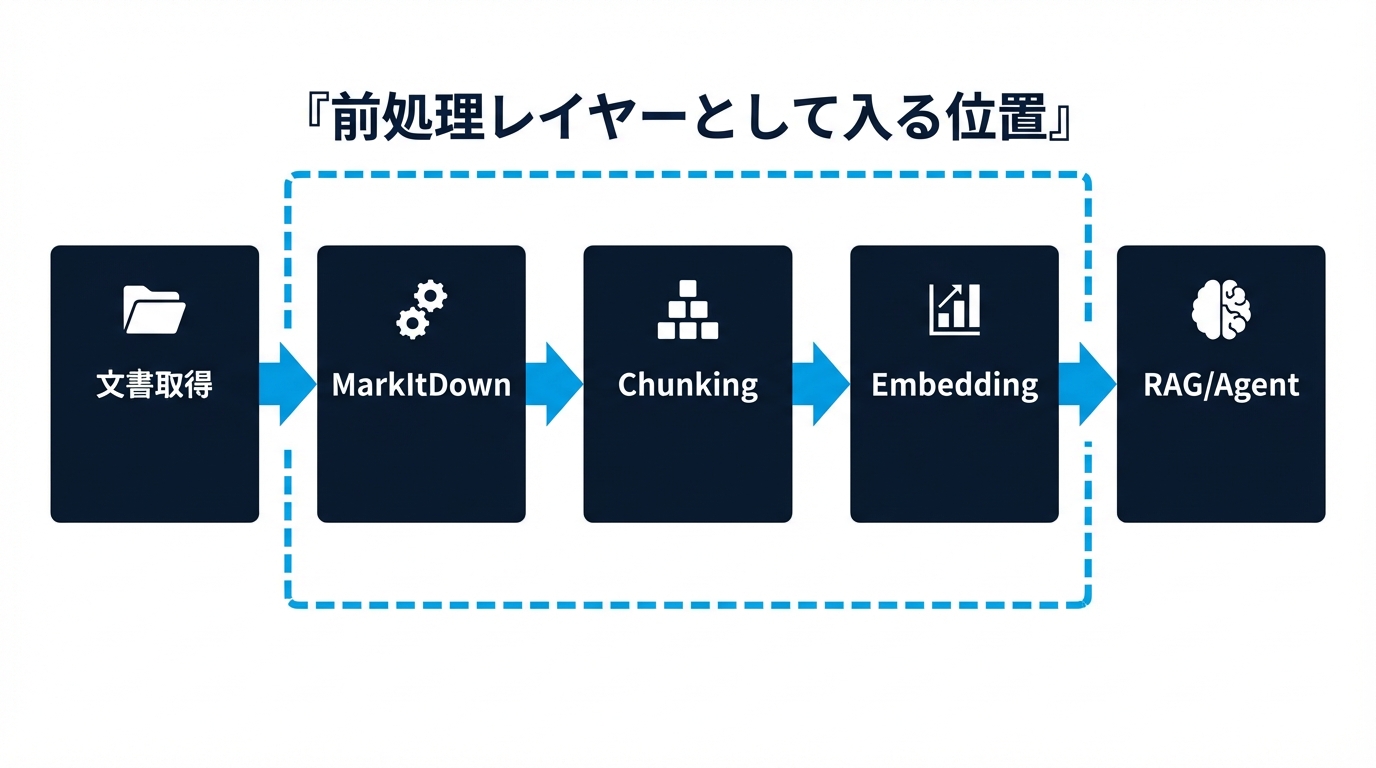
MarkItDown が入る位置はかなり明確です。文書取得の直後、埋め込みや要約の手前です。たとえば業務システムやエージェント基盤では、次のような流れに置きやすいです。
- ファイルや URL を取得する
- MarkItDown で Markdown に変換する
- chunking・metadata 付与・ベクトル化を行う
- 検索、要約、抽出、回答生成へ渡す
この位置づけが分かると、MarkItDown を過大評価しなくて済みます。これは万能 OCR 製品でも、レイアウトを完全再現する DTP 変換器でもありません。README でも「人間向けの高忠実度変換には最適とは限らない」と明記されています。狙いは、あくまで text analysis tools 向けです。
一方で拡張余地は広いです。optional dependencies で PDF、DOCX、PPTX、XLSX、音声転写、YouTube 転写、Azure Document Intelligence 連携を有効化でき、プラグイン機構も用意されています。さらに markitdown-ocr プラグインでは PDF、DOCX、PPTX、XLSX に埋め込まれた画像を LLM Vision で OCR でき、スキャン PDF はページ全体 OCR にフォールバックします。README の時点でも、MCP サーバー markitdown-mcp が用意されており、ローカルの trusted agent から convert_to_markdown(uri) を叩けます。つまり単発ツールではなく、エージェントの前処理サービスとして組み込みやすい設計です。
実務で効く使いどころと、先に知っておくべき限界

実務で効くユースケースはかなり想像しやすいです。たとえば、提案資料や議事録をナレッジ化して社内検索に流す、監査資料や仕様書を Markdown にそろえて差分確認をする、問い合わせ添付の PDF・画像・Excel を LLM に渡す前に共通形式へ変換する、といった場面です。ZIP をたどれるので、案件フォルダ一式の前処理にも向きます。
ただし、限界も先に理解しておいた方がいいです。
- 高精度なレイアウト再現が目的なら別ツールの方が向く
- 画像内テキストやスキャン文書は、標準だけでは弱く、OCR プラグインや外部サービスが必要になる
- optional dependencies を整理しないと、使える形式と使えない形式が混ざる
- MCP サーバーは認証なしで、README でも localhost 以外へ bind しないよう強く注意されている
このあたりは、導入時の設計論に直結します。MarkItDown は「雑多な文書を AI が読める状態にそろえる」役割に非常に強い一方で、文書理解のすべてを単独で解くわけではありません。だから実務では、MarkItDown を正規化レイヤー、OCR や Document Intelligence を補完レイヤー、RAG や agent runtime を活用レイヤーとして分けて考えるのがきれいです。
microsoft/markitdown は派手なデモよりも、AI 文書処理の土台を真面目に作っている OSS です。パッケージメタデータでは Adam Fourney が author として記載され、GitHub でも複数コントリビュータで継続開発されています。もし自社で「PDF ごとに別処理」「Office 文書だけ別パーサ」「画像添付で急に精度が落ちる」といった前処理の歪みを抱えているなら、まず揃えるべきはモデルではなく入力かもしれません。そういう意味で MarkItDown は、AI エージェントを賢くする前に、AI が迷わず読める地面を作るための良い出発点です。より実務寄りに文書処理からエージェント接続まで設計したい方は、サービス詳細 もどうぞ。
関連記事
Next Step
AIエージェント導入、まずは30分の無料相談から
「自社に合うのか?」「何から始めればいい?」
貴社の状況をヒアリングし、最適なAI活用プランをご提案します。