OneCompが示すGPU最適圧縮の実用化
Yuma Ichikawaさん(@yuma_1_or)が公開した OneComp は、単なる「新しい圧縮ツール」ではありません。ポイントは、GPUごとに最適化された圧縮モデルをワンライナーで生成できるようにし、これまで半ば固定観念のように扱われてきた GPTQ 系の標準設定を見直す可能性を示したことです。LLMやVLMの推論コストが問題になる2026年において、圧縮は研究テーマであると同時に、実運用のボトルネックを左右するインフラ技術でもあります。この記事では、OneComp の本質を「モデルを小さくする技術」ではなく、「GPU資源に合わせて最適な圧縮を自動で作る実用フレームワーク」として整理します。
OneCompの本質は“圧縮手法”ではなく“圧縮の自動最適化”
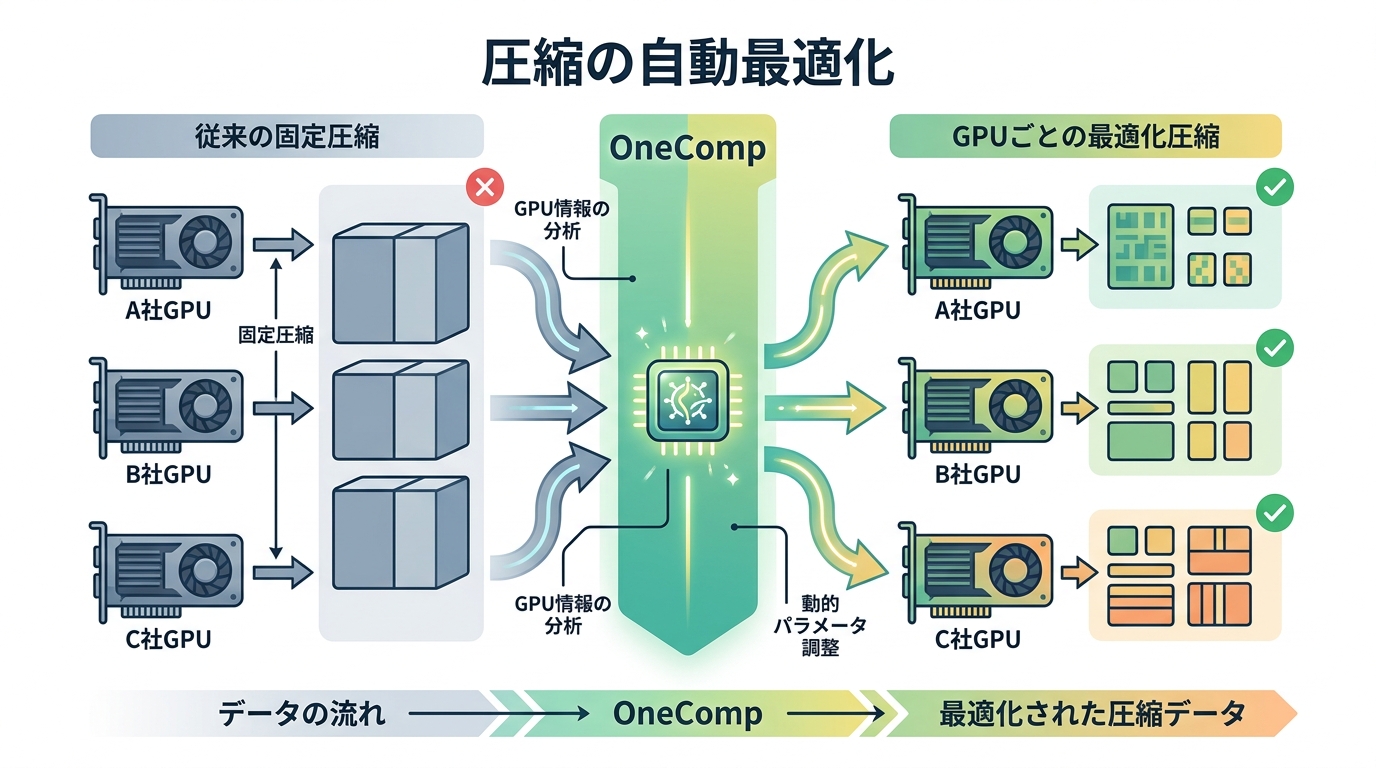
OneComp の第一印象は、open-source compression framework という言葉に引っ張られがちです。しかし本質は、圧縮アルゴリズムを1つ追加したことよりも、GPU環境に最適化された圧縮モデルを自動生成する枠組みを出したことにあります。従来は GPTQ のような既存方式を前提に「とりあえずこれで回す」運用が多く、GPU構成やモデル特性に合わせた最適化は一部の詳しい人しか触れませんでした。
OneComp はこの部分を抽象化し、GPUに合わせてより軽く、より速く、より賢い圧縮を作る方向に寄せています。つまり、圧縮手法の比較ではなく、圧縮の運用レイヤーを作り直そうとしている点が重要です。
なぜGPU最適化が重要なのか
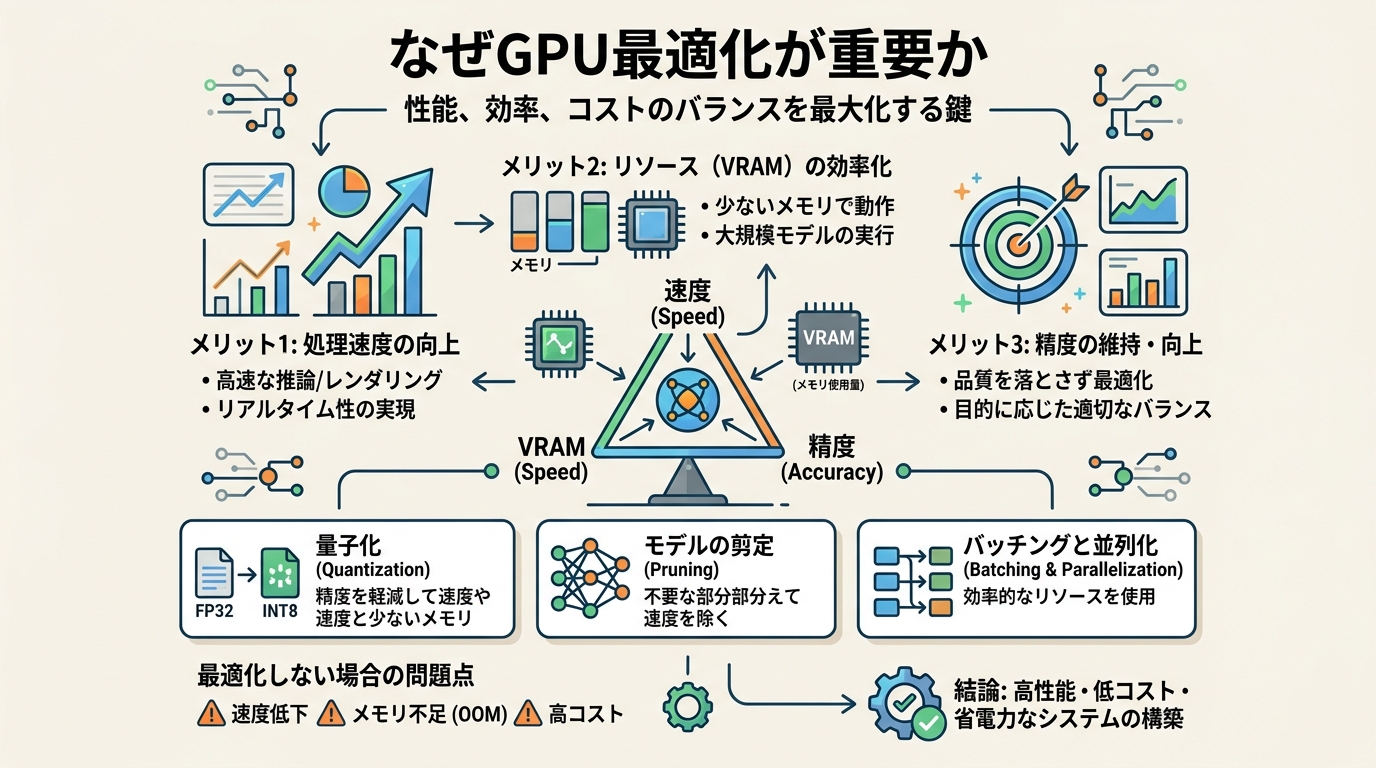
2026年のAI実装では、モデル性能だけでなく「どのGPUで、どの精度で、どの速度で回せるか」が事業性を決めます。特に企業内利用や推論基盤では、同じモデルでも GPU の種類、VRAM 制約、バッチ条件、レイテンシ要件によって最適解が変わります。
このとき圧縮は、単にモデルを小さくする技術ではありません。実際には、
- どのGPUで最も効率よく動くか
- どこまで軽くしても精度を落としすぎないか
- 既存の標準手法より良い運用条件を作れるか
を決めるための実装技術です。OneComp が示しているのは、圧縮を研究者だけのものにせず、推論基盤の実務へ近づける方向です。
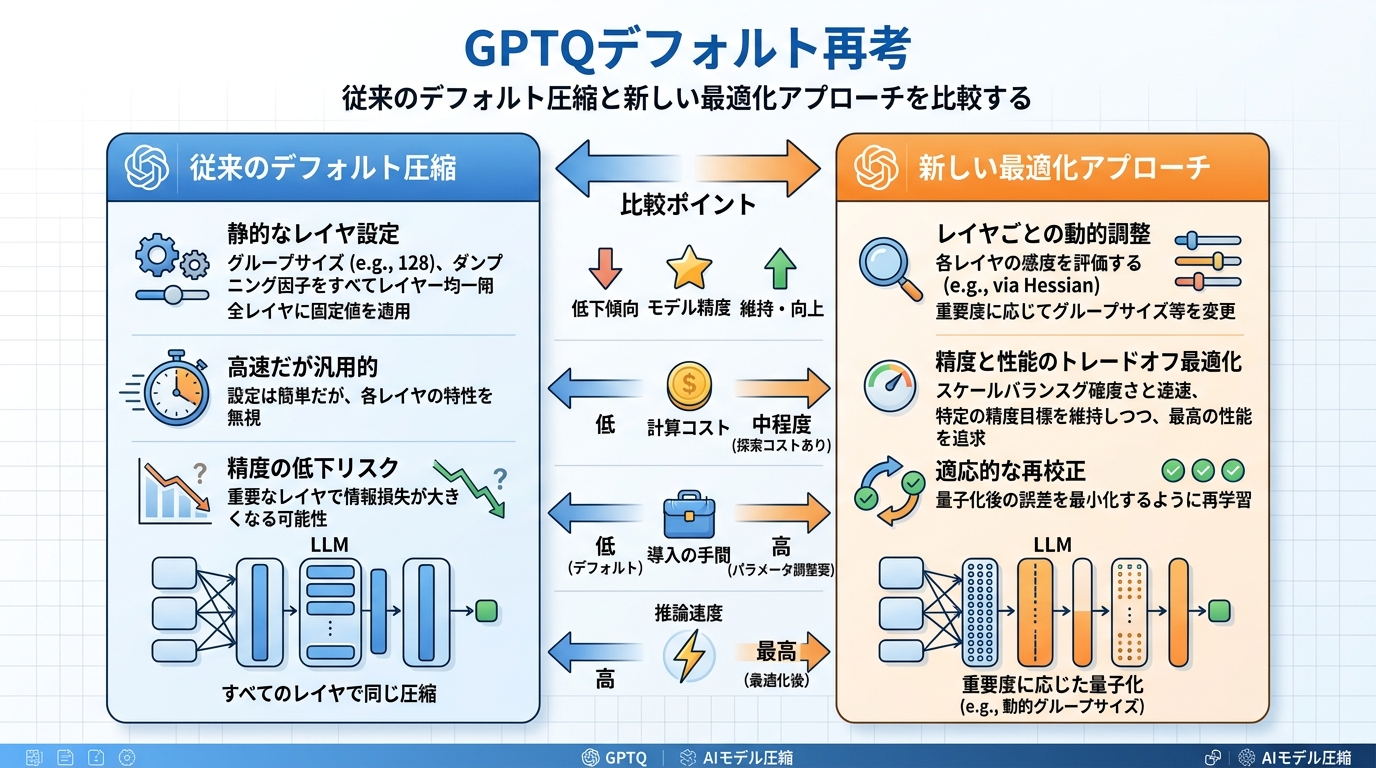
GPTQの“デフォルト”を見直す意味
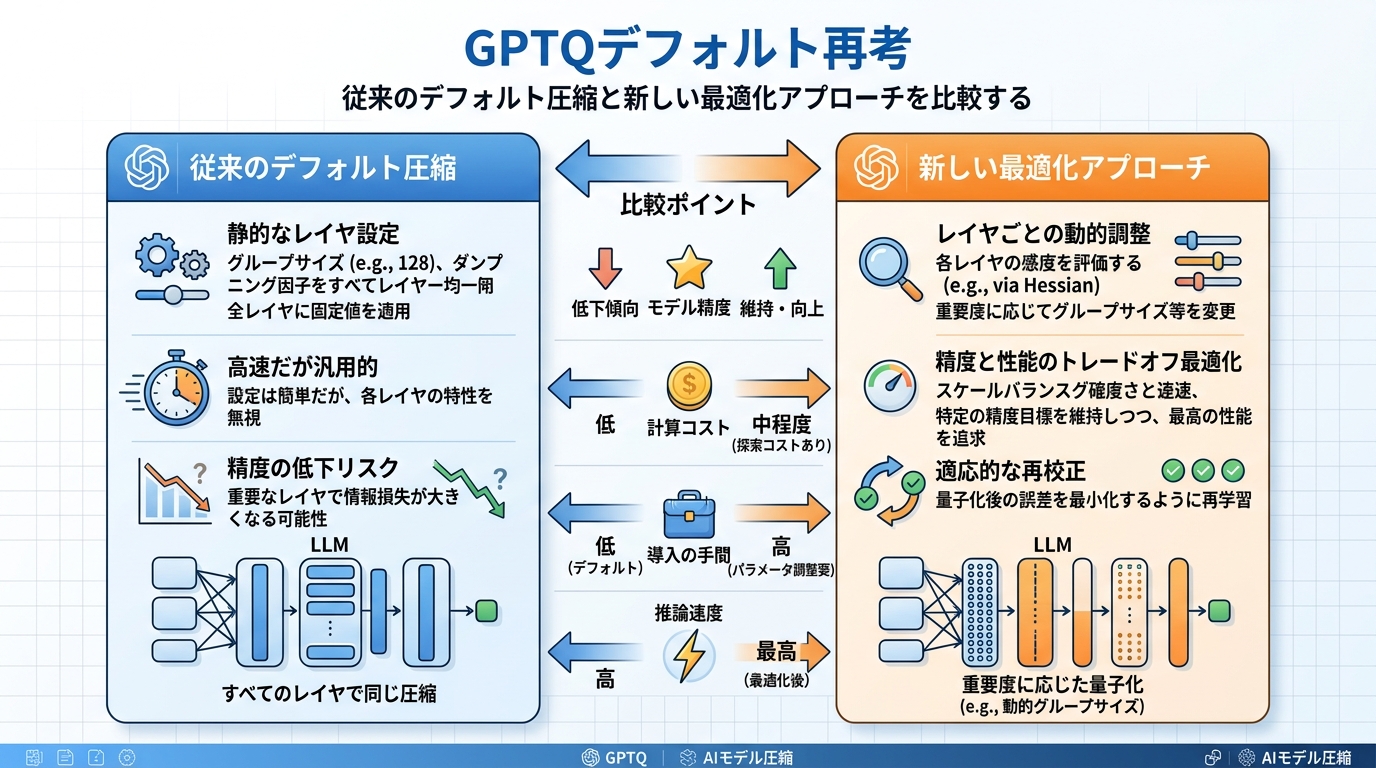
元投稿の中でも印象的なのが、「Goodbye to GPTQ as the default」というメッセージです。これは単なる煽りではなく、長くデフォルト扱いされてきた圧縮の前提を再考すべきだ、という問題提起として読むべきです。
技術領域では、標準があること自体は便利です。ただし、標準が惰性で使われ始めると、GPUやモデルの進化に対して最適化が止まります。OneComp が面白いのは、「圧縮方式の勝ち負け」ではなく、「なぜその方式がデフォルトなのか」を問い直し、GPUごとに最適な圧縮生成へ寄せているところです。
この視点は、推論コストの高止まりや GPU 資源不足に悩むチームにとってかなり実務的です。圧縮はもう、最後の微調整ではなく、モデル運用そのものの設計論点になっています。
研究成果を“使える実装”へ橋渡しする好例
OneComp を見ると、研究成果を OSS として出す価値もよく分かります。論文やプレスだけだと「すごい技術」で終わりがちですが、フレームワークとして公開されることで、実際のGPU環境で試し、比較し、改善できるようになります。ここが技術クラスタで信頼される発信の強さです。
Yuma Ichikawaさんの投稿が面白いのは、自分の研究や成果を単に宣伝するのではなく、「何が変わるのか」を短い言葉で示している点にもあります。今回で言えば、圧縮の未来を「軽い」「速い」だけでなく、「GPUに合わせて自動で最適化される」ものとして見せたことです。
OneComp は、圧縮研究の一成果というより、AIインフラの実務に近いところで効く OSS として見るべきだと思います。もし元ポストをまだ見ていなければ、Yuma Ichikawaさんの投稿 もあわせて確認してみてください。今後のAI実装では、モデルの大きさより「どの基盤で、どの最適化を前提に動かすか」がますます重要になりそうです。
関連記事
Next Step
AIエージェント導入、まずは30分の無料相談から
「自社に合うのか?」「何から始めればいい?」
貴社の状況をヒアリングし、最適なAI活用プランをご提案します。