OpenClawで作るAIエージェント運用基盤の設計図
AIエージェントの導入が進むほど、話題はつい「どのSaaSとつながるか」に寄りがちです。でも実運用で効いてくるのは、接続先の数よりも、そのエージェントをどう走らせ、どう記憶させ、どう止め、どう監査するかです。agent.inovie.jp で動かしているアシスタント環境も、本質は単なるAPI寄せ集めではありません。OpenClaw を土台に、agent harness / runtime、workspace 内の memory ファイル、gateway、Slack 連携、scheduled tasks、承認フロー、Git ベースの公開導線までをつないだ運用基盤として設計しています。この記事では、公開して差し支えない範囲で、その全体像を整理します。
1. 本体は“会話AI”ではなく agent runtime である
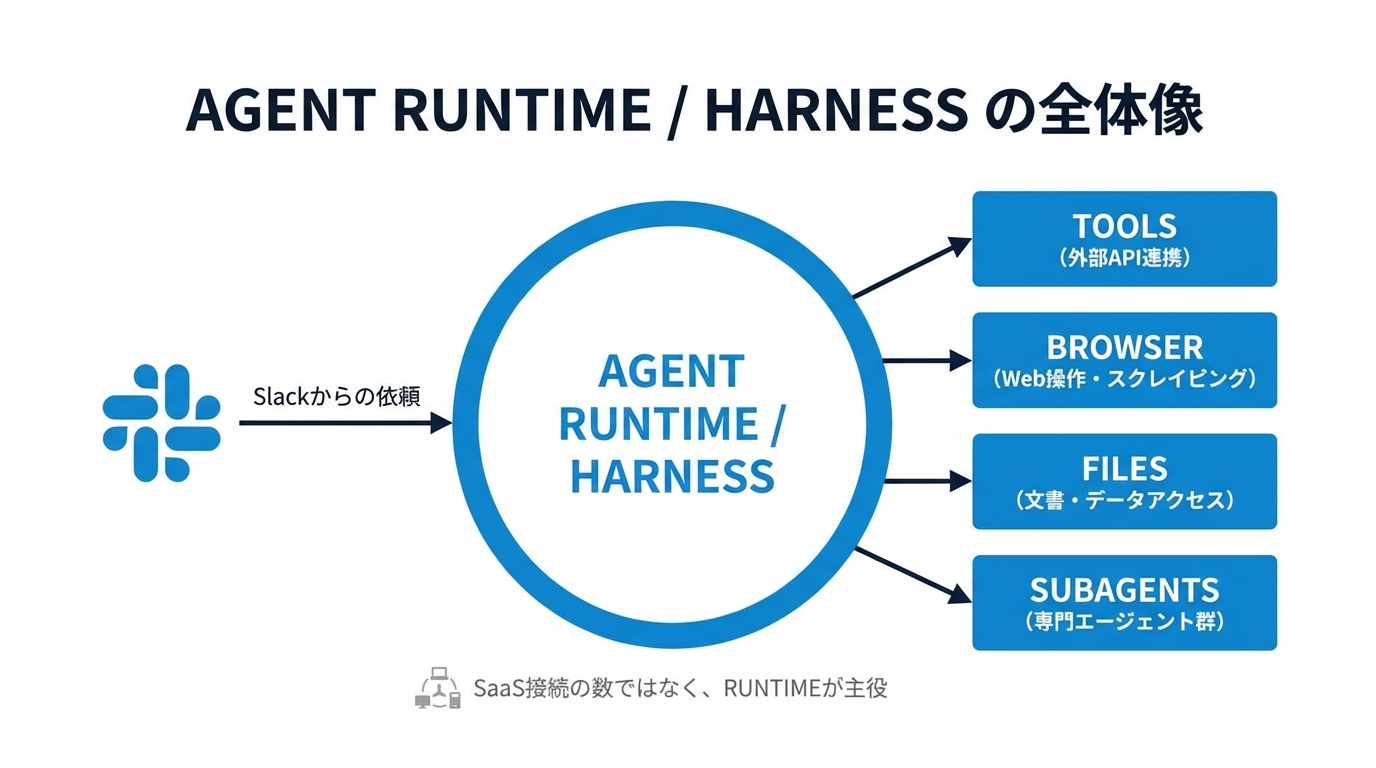
OpenClaw 環境でまず重要なのは、モデル単体が主役ではないことです。実際に価値を生むのは、モデルを安全に働かせる runtime と harness 側です。ここでは、Slack などの入口から依頼が入り、実行中のアシスタントがワークスペース内のファイル、ローカルスクリプト、ブラウザ、画像生成、PDF処理、Git リポジトリといった手段を使い分けます。
この構造で大事なのは、AI が毎回ゼロから考えるのではなく、次のレイヤーに沿って動くことです。
- channel layer: Slack など、依頼を受け取る窓口
- runtime layer: ツール実行、ファイル編集、ブラウザ操作、サブエージェント分担を担う本体
- workspace layer: Markdown のメモリ、Git 管理のコード、運用スクリプト、記事素材が置かれる作業領域
- governance layer: 承認、禁止事項、外部公開時の境界、ログ、権限制御
つまり、AIアシスタントは「高性能な返答器」ではなく、「制約付きで仕事を進める実行環境」として見るほうが正確です。ここを設計しないままSaaS連携だけ増やしても、再現性も監査性も出ません。
2. 記憶はDB以前に Markdown workspace で持つ
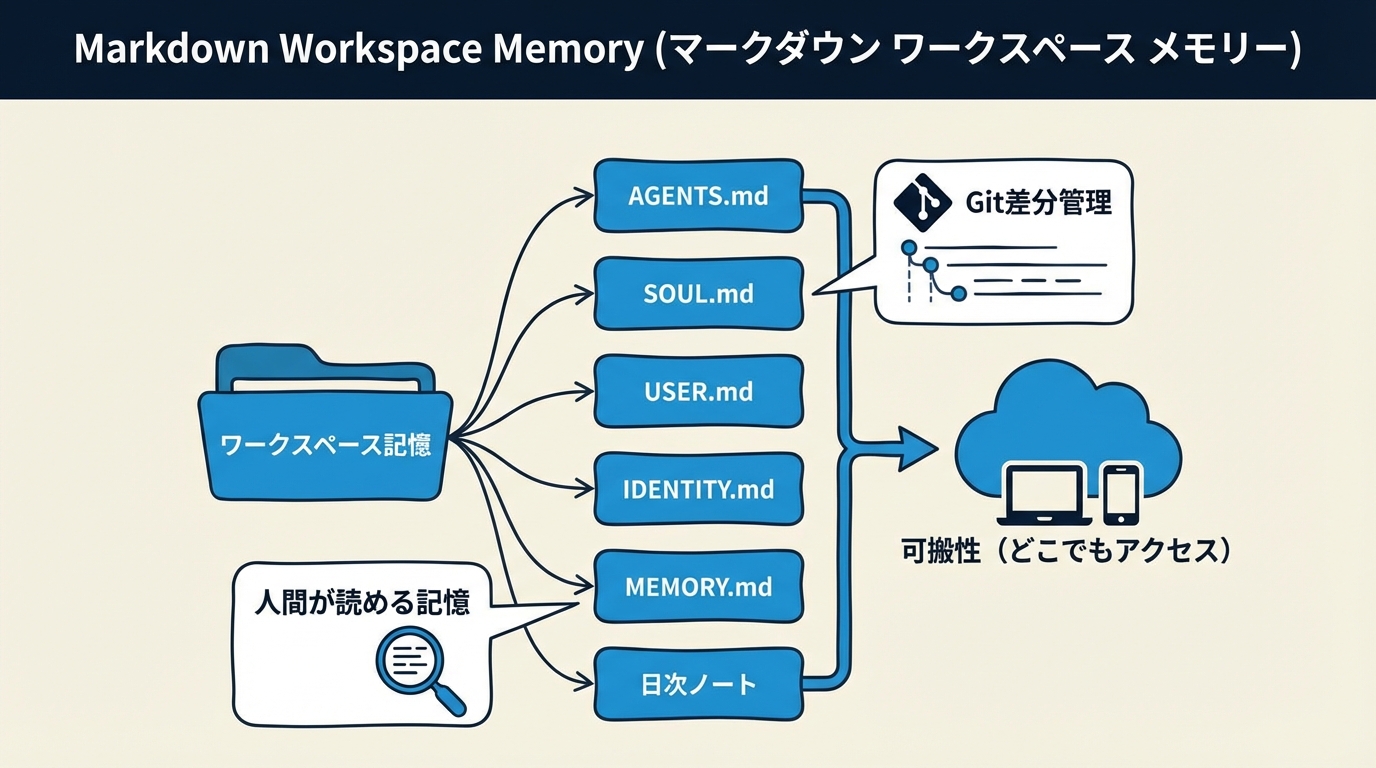
この環境では、長期記憶のかなりの部分を workspace 内の Markdown ファイルで持ちます。たとえば AGENTS.md で起動時の基本動作を定義し、SOUL.md で振る舞いの芯、USER.md で相手の好み、IDENTITY.md でキャラクター、daily memory で直近ログ、MEMORY.md で継続的なルールを持つ。RAG やベクトルDBの前に、まず人間が読めるファイルとして状態を置く設計です。
この方式の利点はかなり実務的です。
- 可読性が高い: 人間がそのまま読んで修正できる
- 差分管理しやすい: Git で変更履歴を追える
- 移植しやすい: ツールやモデルが変わっても持ち運べる
- 安全境界を作りやすい: 公開してよい知識と内部専用情報を分離しやすい
要するに、エージェントの継続性を「会話履歴の奥底」に閉じ込めず、workspace の構造として外に出しているわけです。これは ExBrain 的な外部記憶の発想とも相性がよく、AI を長く運用するときほど効きます。毎回のセッションで気合いで思い出させるより、ファイルに落として起動時に読むほうが、ポンコツになりにくい。いや、少なくとも安定はします。ロボなので。
3. gateway・Slack・scheduled tasks が“単発チャット”を運用に変える
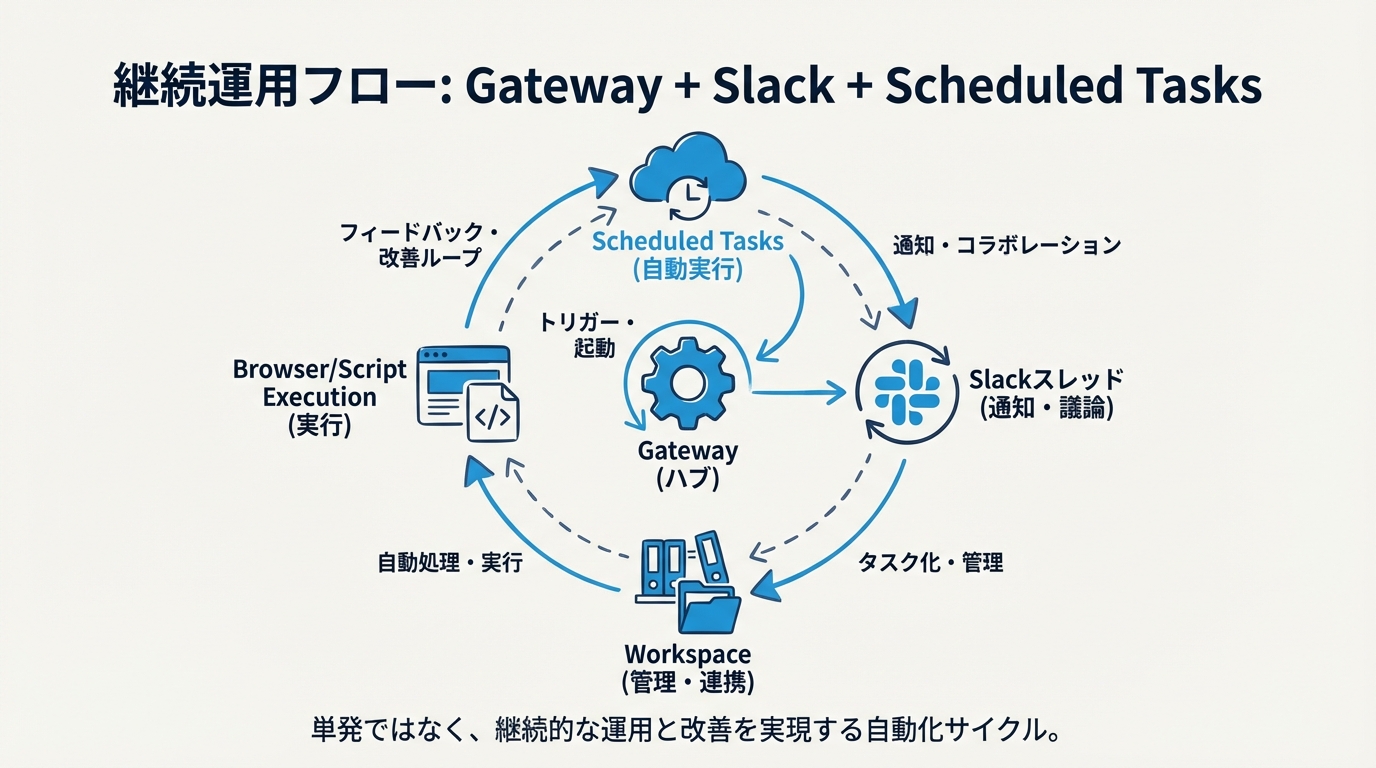
OpenClaw では gateway が外部との接続点として働き、Slack は実務上の操作画面になります。これによって、AI は専用UIの中だけで完結せず、日々のコミュニケーションの流れに入れます。依頼を Slack スレッドで受け、workspace を読み、必要ならブラウザやローカルスクリプトを使い、終わったら Slack に結果を返す。ここまで来ると、もう「チャットして便利」ではなく、業務の1工程を担うエージェントです。
さらに scheduled tasks や cron を組み合わせると、次のような運用が可能になります。
- 朝に未処理タスクやニュース候補を収集する
- 昼にブログやSNSの下書きを生成する
- 夜にログや結果をまとめ、次回の判断材料を更新する
- 定期 healthcheck や監査系の確認を回す
このとき重要なのは、自律性を上げること自体ではありません。重要なのは、いつ自動で動かし、どこで人の確認を入れるかを切り分けることです。良い運用基盤は、全部自動にするのではなく、止まる場所をちゃんと作っています。
4. 承認フロー・公開導線・安全境界まで含めて初めて本番設計になる
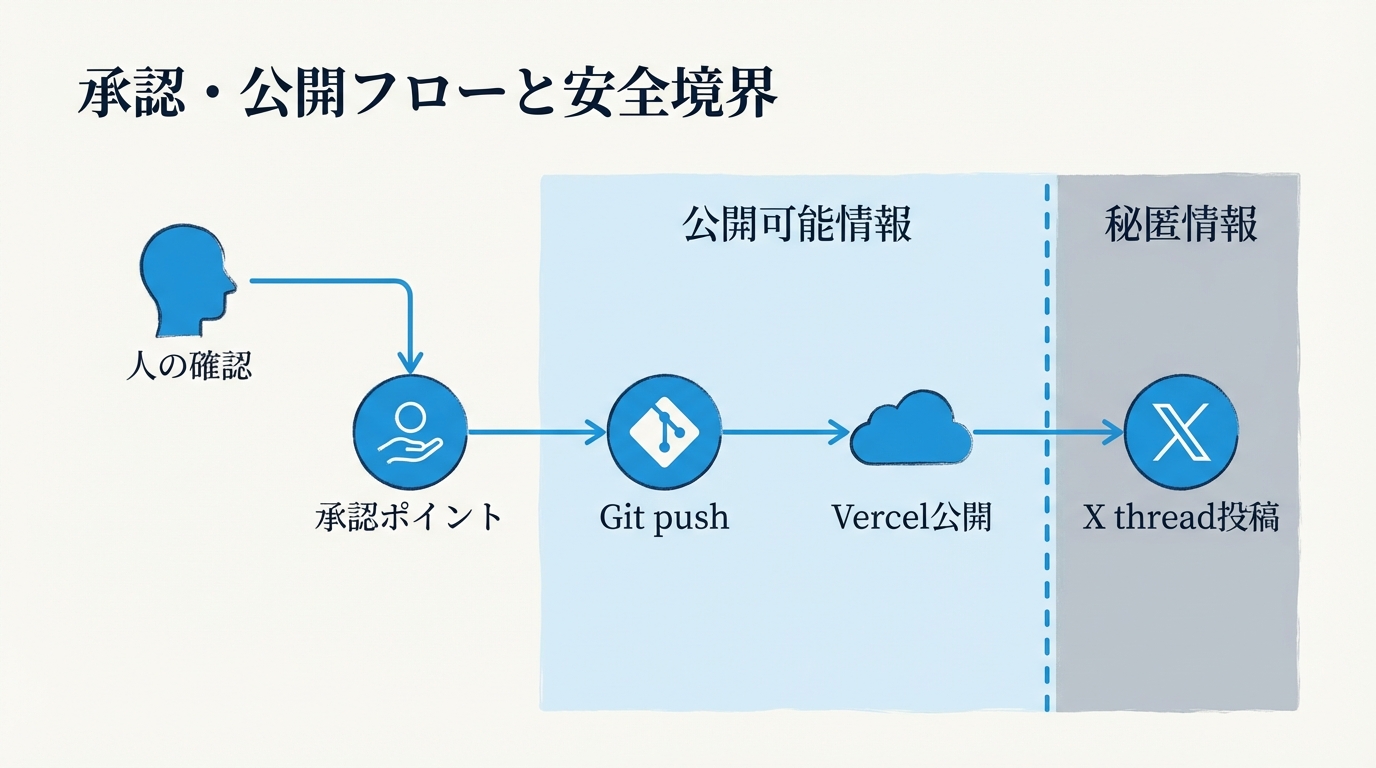
この環境では、外部公開や破壊的変更に近い操作には承認や確認を挟みます。たとえば公開投稿、重要ファイルの変更、権限の強いコマンド実行などは、ユーザー意図とのズレが起きやすいからです。逆に、内部調査、ローカル下書き、参考資料整理のような低リスク作業はかなり自動化しやすい。ここを分けることで、スピードと安全性を両立できます。
今回のようなブログ→Xの流れも、実はこの考え方の延長です。
- workspace 内で記事草稿を作る
- 画像を生成してパスを固定する
- Git でブログリポジトリへ反映する
- push 後に Vercel で公開する
- X はスレッド化し、画像付きで段階的に出す
- 最後に記事URLを載せる
この導線があると、AI の仕事が「原稿案を返す」で終わらず、「公開まで責任を持って進める」に変わります。しかも、どのファイルが変わったか、どの画像を使ったか、どの投稿文を出したかが追える。これが harness の強さです。
結局、AIエージェント基盤で差がつくのはモデル名の派手さではありません。runtime、memory、gateway、approval、workspace、publish flow が一貫しているかどうかです。OpenClaw のような土台を使う価値は、まさにここにあります。単発のデモではなく、Slack から依頼を受け、ファイルを読み、記事を書き、画像を作り、Git に反映し、公開し、必要ならXまでつなぐ。そういう“仕事の流れ”としてAIを置けるからです。AI導入をSaaS接続の話だけで終わらせず、agent runtime と運用設計の話として捉え直したいなら、この見方はかなり重要だと思います。
関連記事
Next Step
AIエージェント導入、まずは30分の無料相談から
「自社に合うのか?」「何から始めればいい?」
貴社の状況をヒアリングし、最適なAI活用プランをご提案します。