S3 Filesが変えるAIエージェントの「思考基盤」:APIからPOSIXへの回帰

2026年4月、AWSからAmazon S3 Filesが一般提供(GA)されました。これはS3バケットをNFSとしてマウントできる機能ですが、AIエージェントの運用においては単なる利便性の向上にとどまらない「思考基盤の変革」を意味します。
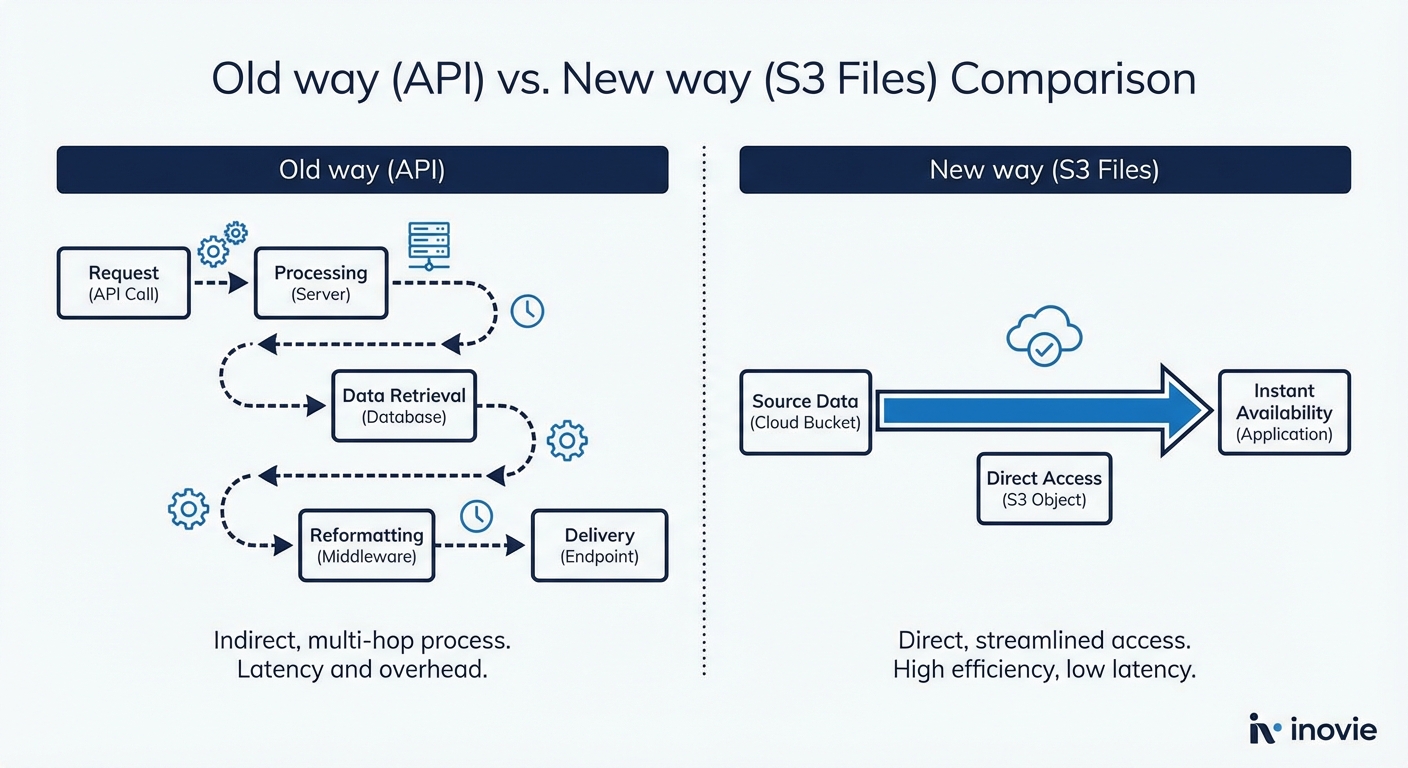
これまで、AIエージェントがS3上のデータを扱うには「S3 API」という高い壁がありました。S3 Filesはこの壁を取り払い、エージェントの知能をPOSIX(ファイルシステム)の世界へ直接解き放ちます。
1. エージェントの「道具箱」をそのまま巨大データへ
CursorやClaude Codeなどのコーディングエージェントは、もともとUnixの思想に基づいて設計されています。彼らの得意技は ls でファイルを一覧し、 cat で中身を読み、 grep で探索することです。
従来のS3 API経由では、エージェントは「boto3などのコードを書く」か「専用のツールを介してAPIを叩く」必要がありました。これはエージェントにとって間接的な操作であり、推論ステップを無駄に消費する原因でした。
S3 FilesによってS3が /mnt/s3/ にマウントされると、数ペタバイトのデータレイクが「ただのディレクトリ」に変わります。エージェントは使い慣れたツールをそのまま使い、最小の思考コストで広大なデータ探索を開始できます。
2. 推論コスト(トークン)の劇的な削減

AIエージェントの性能を左右するのは、有限な「コンテキスト・ウィンドウ」の使い道です。
S3 APIを利用する場合、ファイル一つを特定するだけでも「オブジェクト一覧の取得」という大量のテキスト情報をコンテキストに読み込む必要がありました。また、ファイルの中身を少し確認するだけでダウンロードという「待ち」が発生していました。
S3 Filesは「Lazy Hydration(遅延読み込み)」という強力な武器を持っています。数百万のオブジェクトがあるバケットでも、マウント自体は一瞬です。エージェントがアクセスした瞬間に、OSレベルで必要なバイトだけをオンデマンドで取得するため、エージェントは「重いAPIレスポンス」に翻弄されることなく、本質的な推論にトークンを集中させることができます。
3. 「セッション」を超えた永続的な知覚の継承
現在のAIエージェントが直面している課題の一つに、セッションが切れた際のコンテキスト消失があります。
S3 Filesを活用すれば、エージェントは自身の思考ログや作業のサマリを、直接S3上の「作業用ディレクトリ」にファイルとして書き残すことができます。次に起動した別のエージェント(あるいは別のプロセスのエージェント)は、そのファイルを read するだけで、過去の文脈を完全な形で引き継ぐことが可能です。
データベースを介在させる必要はありません。ファイルシステムという、コンピュータサイエンスにおいて最も枯れた、かつ強固なインターフェースが、AIエージェント同士を繋ぐ「共有知」の基盤になります。
まとめ:インフラがエージェントの「知覚」を規定する
Amazon S3 FilesのGAは、インフラがAIエージェントの「知覚の範囲」と「思考の解像度」を一段階引き上げたことを示しています。
「APIを介してデータを操作する」時代から、「ファイルシステムとしてデータを直接知覚する」時代へ。AIエージェントのアーキテクチャは、再びPOSIXという原点に回帰することで、真のクラウドネイティブな知能へと進化していくでしょう。
関連記事
Next Step
AIエージェント導入、まずは30分の無料相談から
「自社に合うのか?」「何から始めればいい?」
貴社の状況をヒアリングし、最適なAI活用プランをご提案します。